Use Super-resolved Satellite Images to Boost Object Detection Performance
Introduction
Today we are going to talk about object detection in the satellite images.
Previous research runs object detection models on the 30 cm/px resolution data. 30 cm/px stands for 30 cm per pixel, meaning that each pixel in the satellite images represent a 30 cm × 30 cm square on the ground.
The resolution of this dataset is pretty decent in terms of overhead imagery. In fact, this dataset is gathered by airplanes but not satellites. Therefore, it is very hard in reality to get access to a dataset of overhead imagery with this high ground resolution, especially when considering costs and accessibility (it is not allowed to take overhead images using airplanes).
On the contrary, there are tons of free and globally available datasets of satellite imagery that comes with less ground resolution. For instance, USGS launched the Landsat 9 mission providing 30 m/px global images for various bands at no charge.
What if we could utilize a neural network model to generate super-resolved images from low-resolution satellite images so that we could gain an more accessible way to high resolution satellite images anywhere on Earth. In addition, if we could build a baseline object detection model to test how well we does in the super-resolving task, we could quantitively analyze the performance of our super-resolution model in terms of object detection performances. This is what we did in this project.
Experiment Setup
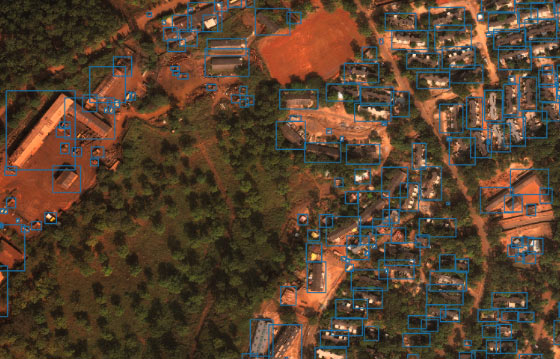
We use xView dataset in our experiment. The xView dataset is a large scale collection of satellite imagery for benchmarking geospatial detection models. These images are taken from WorldView-3 satellites at 0.3m ground sample distance, providing high resolution satellite imagery. The xView dataset also provides high quality annotations for 60 different classes in each image. These object labels can scale from passenger vehicles to container ships. These objects vary in size from 3 meters^2 to greater than 3000 meters^2.
There are 60 different classes in the dataset - significant class diversity containing both land use, cars, and buildings. For our project we have selected 50 images (with resolution around 3200 * 3000) for training and 11 images for testing. The classes shown below are the classes that exist in our subsampled set.
| Class label | Training dataset | Testing dataset |
|---|---|---|
| Building | 59919 | 7076 |
| Small Car | 1951 | 840 |
| Bus | 1254 | 238 |
| Cargo Truck | 805 | 54 |
| Utility Truck | 463 | 48 |
| Vehicle Lot | 456 | 53 |
| … | … | … |
| Dump Truck | 11 | 1 |
| Crane Truck | 10 | 4 |
| Barge | 7 | 6 |
| Truck Tractor | 4 | 16 |
| Fixed-wing Aircraft | 1 | 0 |
| Helipad | 1 | 0 |
In order to perform quantatively analysis on the object detection performance gain from super-resolving, we apply 4 different preprocessing pipelines on the selected dataset (both train and test). For the first one we simply use the original dataset without any further processing and call them High Resolution (HR) images. For the second one we downsampled them to 1.2 m/px (by a factor of 4) and call them Low Resolution (LR) images. For the third one we upsampled the LR images by bilinear interpolation and call them upsampled images. For the forth one we train and apply a super-resolution generative adversarial network (SRGAN) model and call them Super Resoluiton (SR) images. These are shown in the following flowchart.
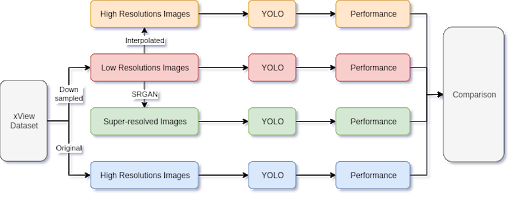
After obtainig these 4 differently preprocessed images, we then independently train 4 object detection model, You Only Look Once (YOLO), on them and evaluate the object detection performance on the test images, respectively.
Super-resolution Model
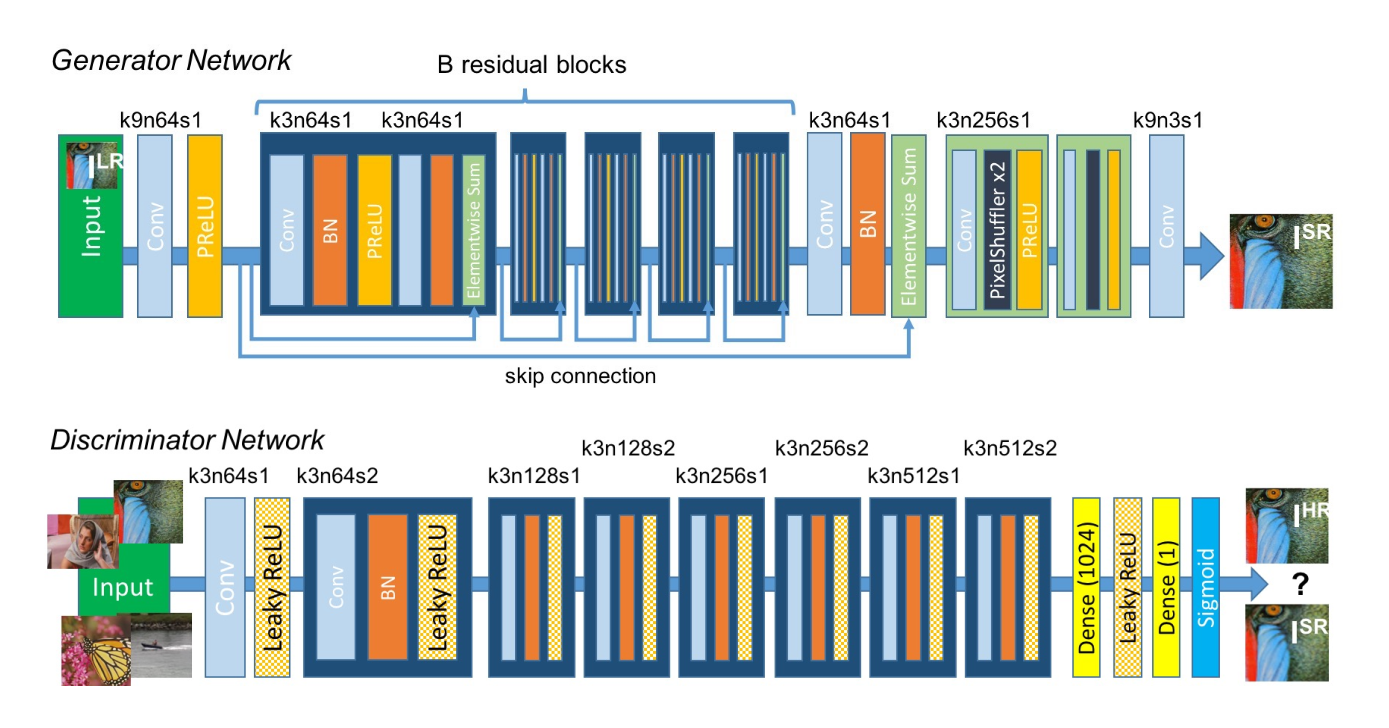
We used a Super-Resolution Generative Adversarial Network (SRGAN) as our super-resolution model to generate SR images. A generative adversarial network (GAN) is a class of machine learning systems which contains two neural networks (a generator, and a discriminator) that compete with each other in a game. Given a training set, this technique learns to generate new data with the same statistics as the training set. A super resolution generative adversarial network (SRGAN) is a GAN that aims to increase the resolution of low-resolution (LR) images by learning the corresponding high-resolution (HR) images . The super resolution process synthesizes sub pixel information in LR imagery to generate super-resolved (SR) images . The LR images are obtained by downsampling operation with downsampling factor . For an image with color channels, we describe by a real-valued tensor of size and , by respectively.
Object Detection Model
You Only Look Once (YOLO)